Ground truth video label annotation
We annotate the video data according to the output of the video-based DIRAC method for human movement and action detection developed by ETHZ:
F. Nater, H. Gabner, T. Jaeggle, and L. van Gool, "Tracker trees for unusual event detection," in Proc. ICCV 2009 Workshop on Visual Surveillance, 2009.
Additionally, we provide ground truth labels that are currently not in use to cover future developments within the DIRAC project and to ensure a reusability of the DIRAC audio-visual database for research apart from the DIRAC project. We define two different classes of labels for annotation. The first class consists of binary labels and is used as an indicator whether a particular action is performed by a single person in the field of view or not. These actions were defined within the DIRAC project for scene descriptions based on a common vocabulary and as representative case studies for the DIRAC application scenarios in-home care and security surveillance
Hengel, P.W.J. van, Andriga, T.C.: Verbal agression detection in complex social environments, in Proc. of AVSS 2007, 2007
Hengel, P.W.J. van,and Anemüller, J.: Audio Event Detection for In-Home-Care. in NAG/DAGA International Conference on Acoustics, Rotterdam, 23-26 March 2009, 2009
The second class are locations of body parts of a person in view, represented as pairs of x and y coordinates in pixels. Both classes, their underlying members as well as their format are summarized in following table:
| class | members | format |
| actions |
Person
|
logical, [0,1]
|
| locations |
Head Location
|
pos. integer [x,y]
|
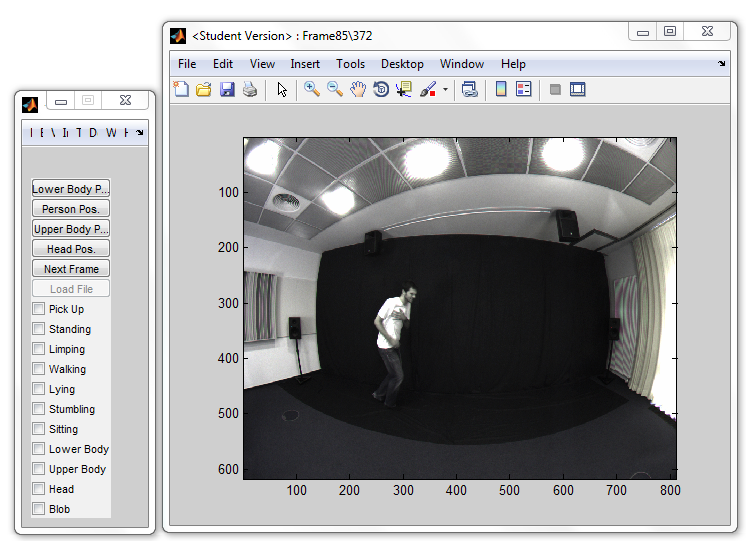
To annotate the video data comfortably, we developed a MATLAB based annotation tool. For each individual video frame, labels can be defined by simply using the PC mouse. The tool consists of two individual windows, a visualization window and a control window. The latter one contains a number of checkboxes for binary label annotation of specific human actions and movements and a number of buttons for manual annotation of the video data according to the location of body parts of a person in view. An snapshot of the video annotation tool can be seen in the figure below. In order to perform the ground truth annotation in a more efficient way, only every third video frame was annotated. The skipped labels and coordinates were generated using linear interpolation using the MATLAB function annotation_interp.m. This is feasible since movements have continuous and/or steady character, which can be handled well using this approach.
The so-derived ground truth labels are then stored in an annotation text file. The file contains the full path to the current frames the ground truth annotations were derived from, the binary labels according to the demands given by the underlying DIRAC method as well as the location and presence of body parts as the absolute position in pixels within a video frame. It is important to note that only single coordinate pairs in x and y directions are annotated instead of a whole bounding box. This is due to the fact that the actual size of an object can change within a scene because of the camera setup and the chosen fish-eye lens such that a bounding box approach would not provide the desired information. Additionally, the bounding boxes generated by the DIRAC methods were not developed for accurate tracking of body parts, but to roughly approximate their locations within the scenes and to provide a visual anchor for the presence of body parts.
Each frame path, its binary labels for actions and location of body parts are separated by a comma. Consecutive frames are separated by a line feed and a semicolon. This has the advantage that the labels can be easily imported for further processing without putting too much effort into text parsing. A text file format was chosen in order to stay independent from the platforms, operation systems and computational frameworks and software development tools such as MATLAB and C/C++. An example of a ground truth annotation file can be found below, whereas the order of the labels per frame is the following: moving object present, head present, upper body present, lower body present, sitting, stumbling, lying, walking, limping, standing, pick up, x coord. of head, y coord. of head, x coord. of upper body, y coord. of upper body, x coord. of person, y coord. of person, x coord. of lower body, y coord. of lower body.
\000001.png, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0;
\000004.png, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0;
\000007.png, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0;
\000010.png, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0;
\000013.png, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0;
...
Ground truth annotation was done on uncalibrated video frames, i.e. directly on the raw data. Despite that the DIRAC methods require pre-processed video frames, evaluation tasks can now be performed directly on raw data, too. Of course, the ground truth annotations can be transformed in such a way that their projections match the camera properties and parameters for camera calibration. Therefore, the MATLAB function annotation2setup.m can be used. This function takes a ground truth annotation text file as an input and transforms coordinates according to the chosen camera setup in a very efficient way. Both the function annotation2setup.m and annotation_interp.m can be found
|
|