Ground truth audio label annotation
Manual labeling for ground truth generation is a very time-consuming process especially for large files and databases. To minimize the working effort, a semi-supervised labeling tool was developed. This tool provides the possibility to visualize the waveform of an audio file and to select multiple segments within the file via mouse clicks for instantaneous playback and individual label creation as it can be seen in the figure:
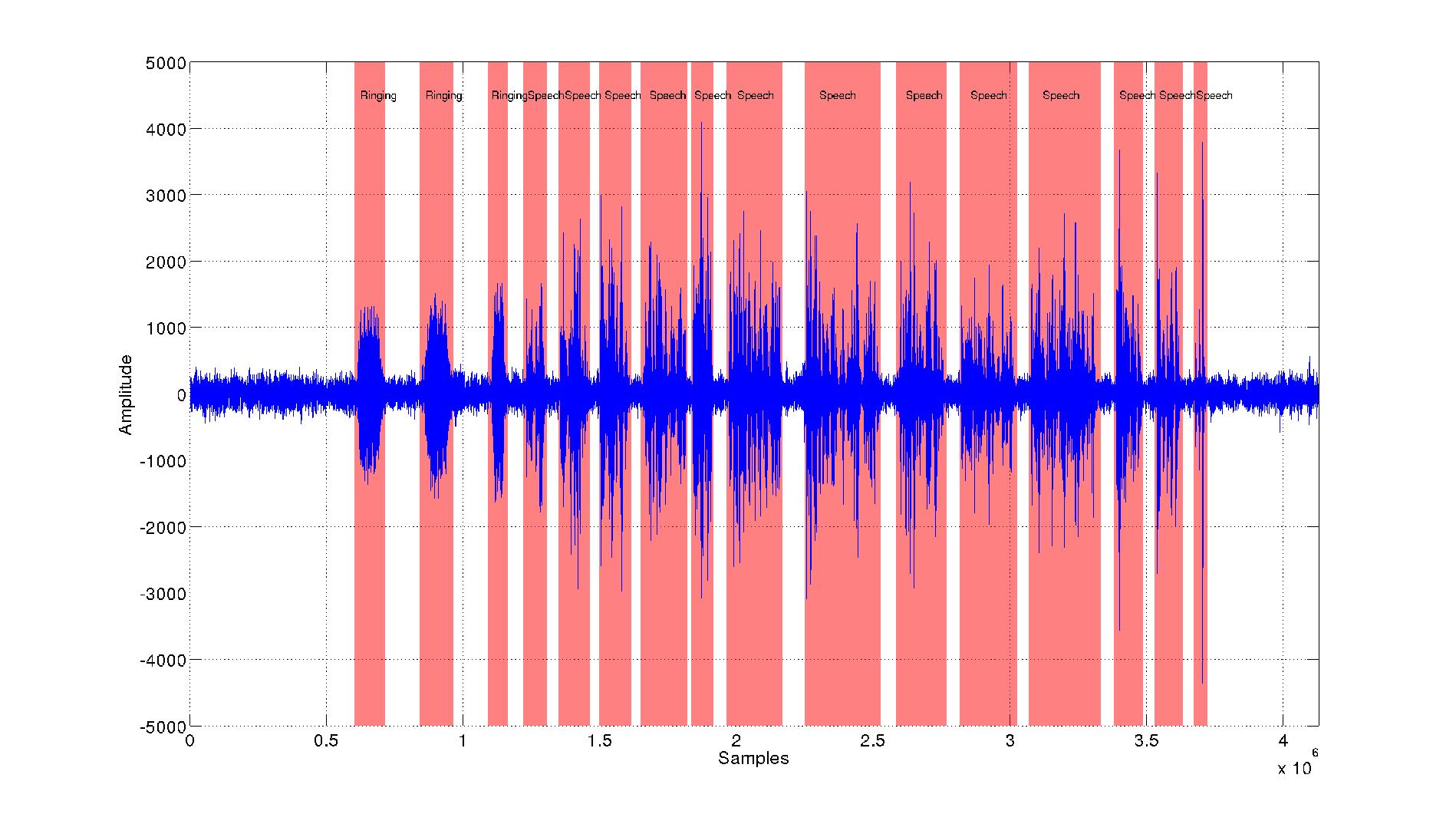
The labels can be defined freely, however, the context of the audio-visual scene, the scene descriptions and the purpose of the recording should be taken into account. Afterwards, the labels and their temporal locations, i.e the start and end sample index of a labeled segment, can be exported in various formats to ensure compatibility with the common office, scientific computation, annotation and machine learning software, such as Microsoft Excel, MATLAB and the HTK Framework.
HTK Speech recognition toolkit. Available online, >>http://htk.eng.cam.ac.uk/<<, 26th August 2010.
For the ground truth label generation, the labels are stored in HTK format. This format has the advantage of a audio file length independent representation of the sample indexes of each label in an audio-visual recording. The HTK representation of the sample index can be calculated using Eq. 1, where S denote the sample index and Fs is the sampling frequency of the actual audio recording.
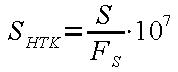 |
(1) |
The original representation can be restored using Eq. 2.
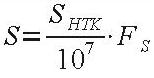 |
(2) |